1. 전체 학습 : epoch X #epochs
: 미니배치 만들어 학습 및 검증을 진행하고 best_model weights를 구한다.
Training ---------> Validation --------------->Epoch 종료 ----------------->Epoch 시작 ---->train
( 매 training epoch이 끝날 때마다 validation을 해준다)
2. Logistic Regression
n차원 입력 벡터를 넣으면 m차원 출력 벡터가 나오는 로지스틱 회귀

3. 시그모이드 함수를 사용하는 이유
- 이 사람은 COVID-19 바이러스에 걸렸는가?
- 입력 : 키, 몸무게, 혈압, 혈중 산소농도, 염증수치
- 출력 : True/False
- = 로지스틱 회귀는 sigmoid를 사용하므로 결과값이 0~1사이 값으로 나옴
- 이진분류 모델에서 오차 함수는 Binary Cross Entropy (BCE) Loss Function
4. Binary Cross Entropy (BCE) Loss Function
- N개의 vector들이 주어졌을 때의 수식(병렬적으로 연산)
- Y값(0 or 1)에 따라 수식의 왼쪽과 오른쪽이 on/off 된다.
- 모델을 DNN으로 만든 후, sigmoind를 마지막에 넣어준다. ->Gradient Descent로 최적화
5. Trade - off by Thresholding
- 지금까지 이진분류할 때 0.5 기준으로 True/False를 판단했는데,
- 0.5를 기준선으로 하지 않는 경우, Threshold에 따라서 성능의 성격이 달라진다.
- -큰 threshold를 가질 경우, 더 보수적으로 True라고 판단 할 것
- 작은 threshold를 가질 경우, 실제 정답이 True인 case를 놓치지 않을 것
5-1 Tresholding, case by case
- 원자력 발전소의 누출감지(True : 누출, False : 정상)
- 단 하나의 누출(True)도 놓치면 안됨.-> Threshold를 작게 잡아야 한다.
- 평가 척도 : Recall이 중요.
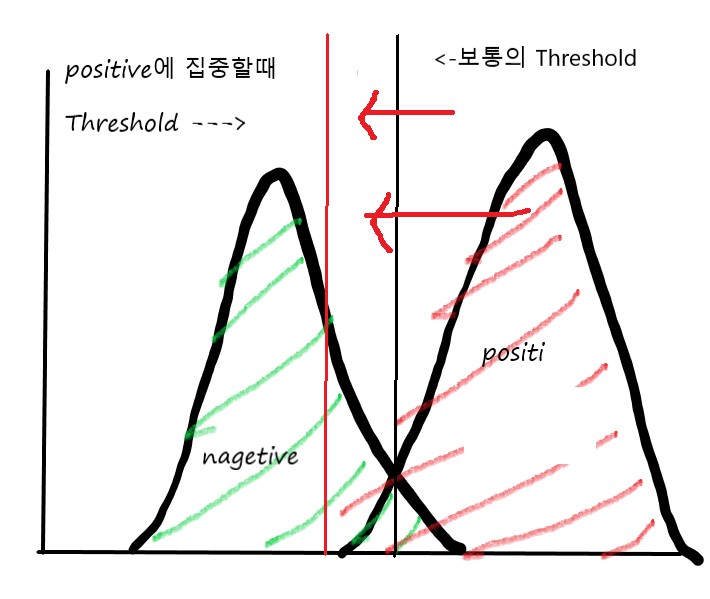
- - 주식 올인 프로그램 (True : 상승, False : 하락, 변동없음)
- - 단 한 건의 하락(False)도 놓치면 안됨
- -> Threshold를 크게 잡아야 한다.
- 평가 척도 : Precision(정확성)
※실습 (유방암 데이터 로드)

<point> : print(df.shape)으로 유방암 데이터 로드 사이즈 확인 칼럼 = 31, index = 569

<point> : df.describe() 함수로 칼럼별 평균(mean) 값과 표준편차(std) 값이 굉장이 다름
<solve> : 표준정규화(standardization)를 이용해 데이터 전처리
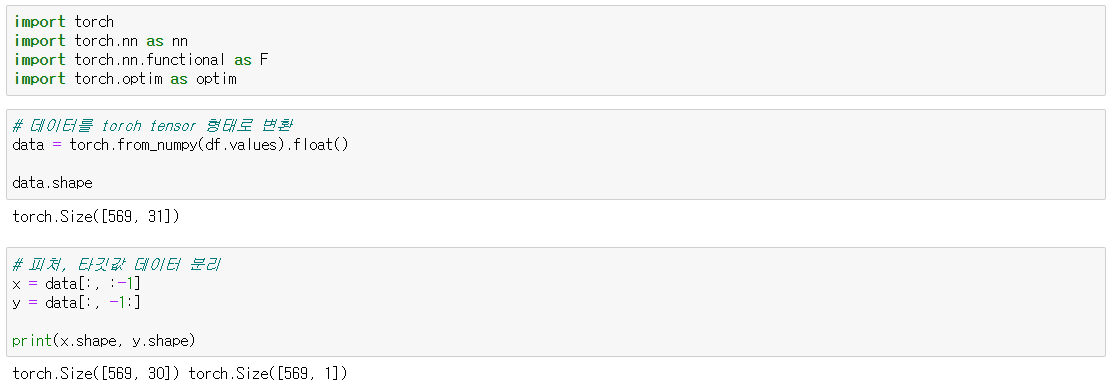
<point> 파이토치를 이용해 데이터를 torch tensor 형태로 변환
data = torch.from_numpy(df.value).float()
피쳐(feature), 타깃값(label) 데이터를 분리.
x = data[ : , : -1 ]
y = data[ : , -1: ]

<point> ratios = [.6, .2, .2] train/ valid / test = 6 : 2 : 2
train_cnt = int(data.size(0) * ratios[0]) --> 569 > 341 train셋 분리

<point> index 셔플 , 데이터를 섞어준다. , 셔플된 인덱스 데이터 값을 x의 저장. torch.index_select() 함수
x = torch.index_select(x, dim=0, index = indices)

for x_i, y_i in zip(x, y ):
print(x_i.size(), y_i.size()) x 변수 안에 (train, valid, test)로 분리 돼 있다.
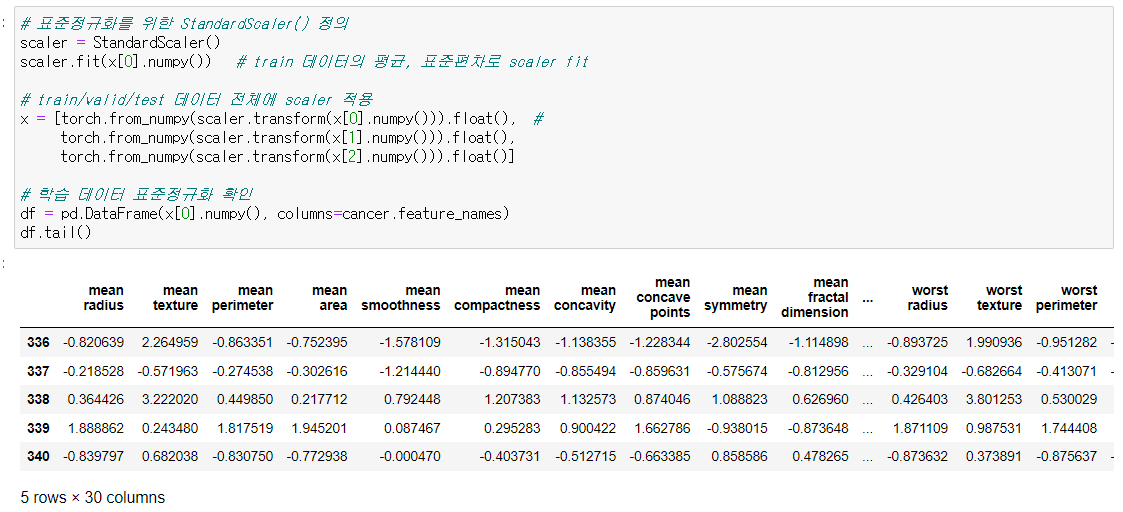
scaler = StandardScaler()
scaler.fit(x[0].numpy()) #train 데이터의 평균,표준편차로 fit ! 이후 나머지 valid, test데이터에도 적용.

<point> model 정의 , x[0].size(-1) = 30 , 입력 데이터 첫 번째 30차원을 받아서 25차원으로 !
활성화 함수 LeakyReLU( ) 란?
입력 값이 음수일 때 완만한 선형 함수를 그려준다.
# 옵티마이저 정의 (고급경사하강법 Adam 사용)
optimizer = optim.Adam(model.parameters())
train_history, valid_history = [], []
# 첫번째 for문은 epoch에 대한 for문이고,
for i in range(n_epochs):
# 학습 데이터(341)에 대해서 랜덤 셔플링하고,
indices = torch.randperm(x[0].size(0))
x_ = torch.index_select(x[0], dim=0, index=indices) # x_, y_ -> train 셋
y_ = torch.index_select(y[0], dim=0, index=indices)
# 배치 사이즈(32)로 균등하게 쪼갠다.
x_ = x_.split(batch_size, dim=0)
y_ = y_.split(batch_size, dim=0)
train_loss, valid_loss = 0, 0
y_hat = []
# 두번째 for문은 한 epoch 내 미니배치에 대한 for문
for x_i, y_i in zip(x_, y_):
y_hat_i = model(x_i)
loss = F.binary_cross_entropy(y_hat_i, y_i) # 이진 분류이므로 F.binary_cross_entropy
optimizer.zero_grad() # parameter들의 grad를 0으로 초기화
loss.backward() # loss 미분
optimizer.step() # 한걸음 걸어간다 : parameter 업데이트(LR x gradient 이용)
train_loss += float(loss) # loss를 float로 만들어 total loss를 계산한다.
# 평균 train loss를 구한다.
train_loss = train_loss / len(x_)
# validation(backward가 필요 없으므로 no_grad 세팅) with torch.no_grad()
with torch.no_grad():
x_ = x[1].split(batch_size, dim=0)
y_ = y[1].split(batch_size, dim=0)
valid_loss = 0 #검증셋 담을 변수 만들고
for x_i, y_i in zip(x_, y_):
y_hat_i = model(x_i)
loss = F.binary_cross_entropy(y_hat_i, y_i) #검증셋 이진 분류이므로 F.binary_cross_entropy
valid_loss += float(loss)
y_hat += [y_hat_i] #
# 매 epoch마다 validation loss를 구한다.
valid_loss = valid_loss / len(x_)
train_history += [train_loss]
valid_history += [valid_loss]
if (i + 1) % 100 == 0:
print('Epoch %d: train loss=%.4e valid_loss=%.4e lowest_loss=%.4e' % (
i + 1,
train_loss,
valid_loss,
lowest_loss,
))
# 만약 validation loss가 갱신되었다면, best model로 저장
if valid_loss <= lowest_loss:
lowest_loss = valid_loss
lowest_epoch = i
best_model = deepcopy(model.state_dict()) # best_model에 모델 상태 저장
else:
# early stop을 적용할지 체크
if early_stop > 0 and lowest_epoch + early_stop < i + 1:
print("There is no improvement during last %d epochs." % early_stop)
break
print("The best validation loss from epoch %d: %.4e" % (lowest_epoch + 1, lowest_loss))
'딥러닝 > 이론 정리' 카테고리의 다른 글
| BPE알고리즘 과 텍스트 전처리 과정 (0) | 2021.08.05 |
|---|---|
| NLP의 기본 자연어 처리 (0) | 2021.08.02 |
| 파이토치 오토인코더 이론에 대해 알아보자 (0) | 2021.07.30 |
| 원 핫 인코딩의 한계와 Vector Embeding의 필요성 (0) | 2021.07.30 |
| 딥 러닝 차근차근 이론 정리. (0) | 2021.07.02 |



댓글